Introduction
In December 2021 I was working on a problem from the Advent of Code 2021 that required getting all elements from two collections that were contained in both of them. In Kotlin, there is an extension function for that use case on Iterable called intersect.
In my case, the first collection was a regular List and the second one was a Set.
The code that I eventually used was analogical to this one:
val x = (1..1_000_000).toList()
val y = (1..100_000).toSet()
x intersect y
However, when refactoring the code, I incidentally changed the order of the operands and the last line became y intersect x.
Given the fact it was the only modification to the code I made, I was genuinely surprised to find that my program now runs a couple of times slower.
That led me to run some experiments to verify whether this seemingly irrelevant change really affects the performance such drastically or the reason was to be found somewhere else.
The experiment
I decided to use the same code introduced above and measure the execution time separately for both variants:
- For
x intersect y. - For
y intersect x.
For each variant, the experiment was repeated 20 times on my machine (MacBook Pro 13-inch, early 2015) and the average time was obtained.
Full code for the experiment:
val results = mutableListOf<Long>()
repeat(20) {
measureTime {
val x = (1..1_000_000).toList()
val y = (1..100_000).toSet()
x intersect y // or y intersect x
}.inWholeMilliseconds.also { results.add(it) }
}
print(results.average())
Here are the results:
| Variant | Time |
|---|---|
x intersect y | 224 ms |
y intersect x | 4793 ms |
As you can see, the outcome is quite surprising. What’s more, the bigger the y collection, the greater the time difference between those two variants.
Findings
Overall, as I dig deeper into the topic (including the source code of the intersect function), I realized that the problem is not the order of the operands itself, but rather the fact that the second operand in the slower variant was not of type Set.
Moreover, this problem only exists starting with Kotlin 1.6. In prior versions, both of those tested variants (x intersect y and y intersect x) would yield the same results. That’s why it might be worth providing a little story behind this issue:
Before Kotlin 1.6
In many cases, when running some of the Collection operations (such as aforementioned intersect, minus, removeAll or retainAll), Kotlin tried to optimize them by converting their second operands to a Set under the hood.
Why would it do that?
Let’s consider the minus operation. It returns a list consisting of elements from the first collection that are not present in the second collection. It does that by filtering the first collection to keep only the items that are not in the second collection. But how does it know that a specific item is not present in that collection? By calling its contains method.
Typically, the complexity of checking for the existence of an item in a regular list or array is linear. We have to go through each item one by one. On the other hand, that complexity is reduced to a constant time for sets. To check whether an item is present in the set, it is enough to compute its hash code.
For that specific reason, Kotlin tried to introduce this optimization any time it could to improve the performance. But it was not possible in all cases.
The problem was that a collection could override its contains method causing some unexpected behavior down the road.
For instance, imagine we pass a collection with overridden contains method that we count on (for example, an IdentitySet). Kotlin then converts it under the hood to a different type - a HashSet. With this change, we can no longer rely on our custom contains implementation because the initial collection is now of another type. This could lead to some errors that are difficult to debug.
That is why the optimization was applied only in specific cases:
- When the operand was not implementing a
Collectioninterface (meaning it could not override itscontainsmethod). - When the operand is a known implementation of Collection that doesn’t override
contains(currently onlykotlin.collections.ArrayList)
However, as it turned out, this optimization was quite problematic for a few reasons:
- The code responsible for deciding whether to convert the second operand to a
Setwas quite difficult to read. Therefore, it was not obvious at the first glance if it was going to be converted or not. - Sometimes, we might not be aware of the actual implementation of a specific collection - it could be “hidden” behind some interface. So, we cannot easily deduce whether it would get converted or not.
- There were some problems (described here) leading to incorrect results when any element changed its
hashCodevalue after being placed to the converted set.
Since Kotlin 1.6
For the reasons mentioned above, the Kotlin team decided to remove this optimization entirely. Now, the second operand will never be converted to a Set. At most, it will be converted to a List if the operand is not implementing the Collection interface.
For a full list of affected API, see this link.
Because this decision could potentially cause performance degradation in some cases, an inspection was added to inform about this issue offering an option to manually convert the second operand to a Set.
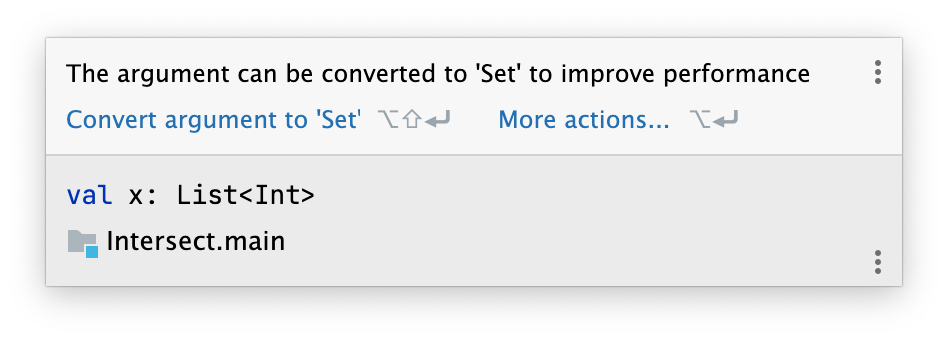
(The argument can be converted to ‘Set’ to improve performance)
For now, it is possible to enable this optimization back on the JVM with a system property (kotlin.collections.convert_arg_to_set_in_removeAll). This will give more time to the developers that were previously relying on this feature to migrate the affected code.
Although, it is worth mentioning that the possibility of enabling the optimization back is planned to be removed in Kotlin 1.7. The same thing is going to happen to the inspection. It will be turned off by default with the next major release. Yet you will be able to turn it on again by going to Preferences -> Editor -> Inspections -> Kotlin -> Other problems.
They give the following explanation for their decision:
However, we expect this inspection to be quite annoying in places where such time complexity does not that matter, so we plan to disabling it by default in the next version of Kotlin and leaving only an intention.
Summary
To summarize, here are the key points from this post:
- Since Kotlin 1.6, the second operands of some Kotlin Collection operations will no longer be converted to a Set under the hood.
- That may have some performance implications, so an inspection was added to inform you about this issue whenever applicable.
- However, the inspection will be turned off by default with the next major release of Kotlin (1.7). You might want to consider turning it on again if you think your codebase might benefit from having it.